Whereabouts London, by Future Cities Catapult
An experiment in how open data can be used to understand and improve future cities
From Jon Snow discovering the source of London’s Cholera outbreak to Charles Booth’s poverty maps, effective use of data has a history of improving city life. The insights it brings can open up huge opportunities for making them cleaner, healthier and more prosperous places to live.
Whereabouts London is an ongoing experiment by the Future Cities Catapult in how open data can be used to help cities and citizens see their environment in a new light. By blending 235 types of data we’re beginning to investigate what London could look like if we drew London’s boundaries afresh, grouping neighbourhoods based on how we live, not where we live.
Future Cities Catapult clustered London into 8 Whereabouts based on similarities between people and places.
Reimagining neighbourhoods in this way could help local authorities to commission shared services, or design and procure shared infrastructure more effectively across existing administrative boundaries. It could help a transport provider to tailor a service more efficiently, make behaviour change campaigns scalable to new areas of a city or reduce start-up costs for innovative new businesses, to name just a few applications.
Whereabouts London uses data from the Greater London Authority’s data store along with other publicly available datasets. The code is open source and we’ve produced a short how-to guide for individuals or organisations to create a Whereabouts for their own city.
By encouraging more Whereabouts we hope to empower cities to help them improve and prosper. Why not have a go? Or perhaps you’re already working on something similar? We’d love to hear about it.
Open Data and the London Datastore
The London Datastore is a hub for data related activities for the city. Using the latest version, users can find, explore and build on over 500 datasets that the city generates, by either downloading datasets, or access through an API . Future Cities Catapult used the Datastore’s new spatial search functionality to help us extract data for neighbourhoods across the city, and merged that with open data from other sources, including the Food Standards Agency, the Office for National Statistics, Land Registry, OpenStreetMap, Flickr and Transport for London.
By bringing information from these different sources together through machine-learning algorithms, we can start to build up a picture of what makes our local areas similar to, and distinct from, each other.
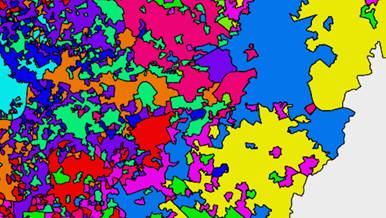
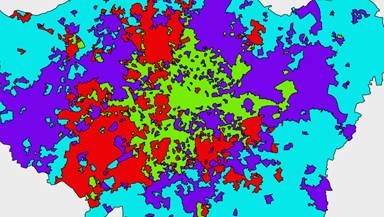
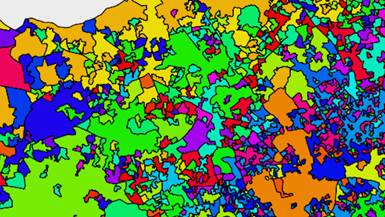

Above are four examples of alternate clusters we created using a variety of other datasets.
Future Cities Catapult used an algorithm called K-Means clustering to help us find neighbourhoods that have similar characteristics. We grouped them together to form the Whereabouts you can explore on the map. Naturally our Whereabouts are only one example of clustering based on our selected criteria – but using this process it would be possible for anyone to create their own map, tailored to their own needs and interests. The code for both the generation of Whereabouts and this website has been released under an Open Source licence and can be accessed here.
Future Cities Catapult